
In today's AI-driven landscape, organizations face a significant challenge: how to build and maintain efficient machine learning operations (MLOps) pipelines without breaking the bank. As AI models grow more complex and resource-intensive, the infrastructure costs associated with training and deploying these models can quickly spiral out of control.
This is where Convox's workload placement and intelligent resource management capabilities come into play. In this comprehensive guide, we'll explore how you can leverage Convox to build a cost-effective MLOps pipeline that optimizes resource usage while maintaining the performance your AI applications need.
Before diving into the solution, let's understand the core challenges:
A properly architected MLOps pipeline with Convox addresses all these challenges through intelligent workload placement, proper resource allocation, and automation.
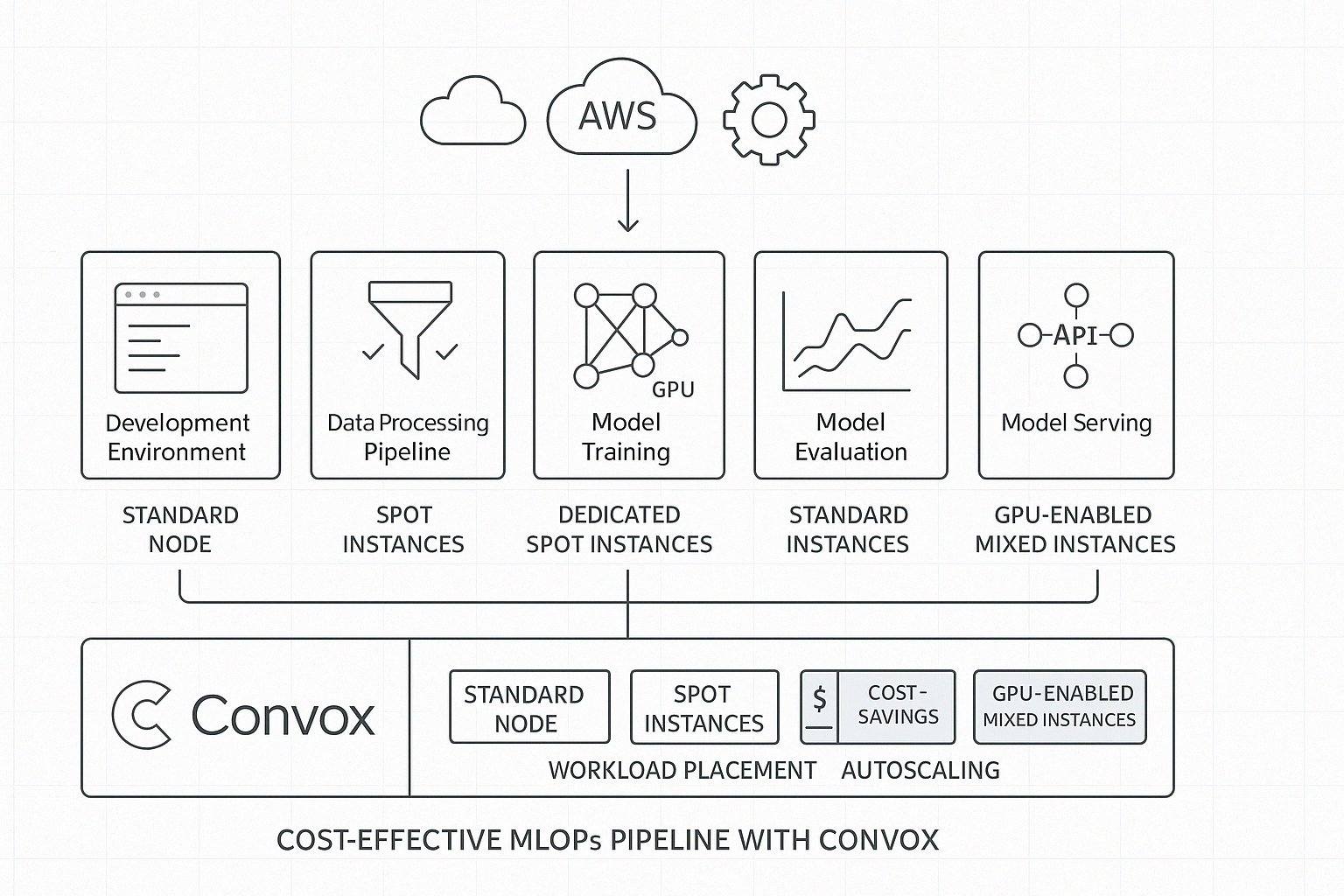
Here's what an optimized MLOps pipeline looks like with Convox:

The pipeline consists of several key components, each with specific resource needs:
Let's explore how to implement each component efficiently using Convox.
The foundation of our cost-effective MLOps pipeline is Convox's ability to create specialized node groups. This feature allows us to tailor our infrastructure to the specific needs of each pipeline component.
First, let's set up three distinct node groups for our MLOps pipeline:
$ convox rack params set additional_node_groups_config=/path/to/node-groups.json -r productionWhere node-groups.json contains:
[
{
"id": 101,
"type": "t3.medium",
"capacity_type": "ON_DEMAND",
"min_size": 1,
"max_size": 3,
"label": "development",
"tags": "team=ml,environment=production,workload=development"
},
{
"id": 102,
"type": "c5.2xlarge",
"capacity_type": "SPOT",
"min_size": 0,
"max_size": 10,
"label": "training",
"tags": "team=ml,environment=production,workload=training",
"dedicated": true
},
{
"id": 103,
"type": "g4dn.xlarge",
"capacity_type": "MIXED",
"min_size": 1,
"max_size": 5,
"label": "inference",
"tags": "team=ml,environment=production,workload=inference",
"dedicated": true
}
]Let's also create a dedicated node group for our build processes:
$ convox rack params set additional_build_groups_config=/path/to/build-groups.json -r productionWith build-groups.json containing:
[
{
"type": "c5.xlarge",
"capacity_type": "SPOT",
"min_size": 0,
"max_size": 3,
"label": "ml-build"
}
]This configuration gives us:
For the development environment, we'll create a service that data scientists can use to explore and develop models. This environment needs to be stable but doesn't require heavy resources.
# convox.yml
services:
jupyter:
build: ./jupyter
port: 8888
scale:
count: 1
cpu: 1024
memory: 4096
nodeSelectorLabels:
convox.io/label: development
environment:
- JUPYTER_TOKENThe nodeSelectorLabels directive ensures this service runs on our designated development nodes, keeping costs predictable while providing sufficient resources for exploration.
Data processing often requires bursts of compute but can tolerate spot interruptions. Let's implement a data processing service that takes advantage of spot instances.
# convox.yml
services:
data-processor:
build: ./data-processor
scale:
count: 0-5
cpu: 2048
memory: 8192
targets:
cpu: 70
nodeSelectorLabels:
convox.io/label: training
command: python process_data.pyThis service:
Training is where costs can explode if not managed properly. Let's set up a training service that maximizes cost efficiency:
# convox.yml
services:
model-trainer:
build: ./trainer
scale:
count: 0
cpu: 3072
memory: 12288
nodeSelectorLabels:
convox.io/label: trainingWait, why set count: 0? Because we'll only run training as one-off processes through timers or manual triggers, not as continuously running services.
# convox.yml
timers:
nightly-training:
schedule: "0 0 * * *" # Run daily at midnight
command: python train_model.py --dataset=latest
service: model-trainer
concurrency: forbid # Prevent overlapping jobsThis approach ensures we only pay for training resources when they're actively being used, and leverages spot instances for significant cost savings (often 60-70% less than on-demand pricing).
For ad-hoc training runs, we can use Convox's run commands:
$ convox run model-trainer python train_model.py --node-labels="convox.io/label=gpu-node-group"This allows data scientists to trigger training jobs as needed, without requiring continuous resources.
For inference, we need reliable performance with GPU acceleration. Our configuration uses a mixed capacity approach to balance cost and reliability:
# convox.yml
services:
inference-api:
build: ./inference
port: 5000
scale:
count: 2-10
cpu: 2048
memory: 8192
gpu: 1
targets:
cpu: 60
nodeSelectorLabels:
convox.io/label: inferenceThis service:
Building ML containers can be time-consuming. Let's direct our builds to the dedicated build nodes:
$ convox apps params set BuildLabels=convox.io/label=ml-build -a mlops-app$ convox apps params set BuildCpu=2048 BuildMem=4096 -a mlops-appThis configuration:
Convox automatically applies the tags we specified in our node group configurations, enabling detailed cost tracking in AWS Cost Explorer.
For instance, you can break down costs by:
team=ml)environment=production)workload=training, workload=inference, etc.)This provides visibility into where your ML costs are going and helps identify optimization opportunities.
For large-scale model training, you might need to implement distributed training across multiple nodes. Here's how you can configure this in Convox:
# convox.yml for distributed training
services:
training-coordinator:
build: ./distributed-trainer
command: python coordinator.py
scale:
count: 1
cpu: 2048
memory: 8192
nodeSelectorLabels:
convox.io/label: training
environment:
- TRAINING_WORKERS=4
- EPOCHS=100
- BATCH_SIZE=64
training-worker:
build: ./distributed-trainer
command: python worker.py
scale:
count: 4
cpu: 4096
memory: 16384
gpu: 2
nodeSelectorLabels:
convox.io/label: trainingThis setup creates:
For effective MLOps, monitoring is critical. You can integrate with Datadog for comprehensive monitoring:
# convox.yml monitoring section
services:
model-monitor:
build: ./monitor
scale:
count: 1
cpu: 512
memory: 1024
nodeSelectorLabels:
convox.io/label: development
environment:
- DD_API_KEY
- MODEL_ENDPOINTS=inference-api:5000
command: python monitor_drift.pyThis service will continuously monitor your deployed models for performance metrics and data drift, sending the data to your monitoring system.
When implementing a properly segmented MLOps pipeline with Convox, organizations typically see substantial cost reductions compared to traditional always-on, uniformly provisioned environments.
By implementing the workload placement strategies outlined in this article, you can typically achieve:
Training Workloads:
Inference Workloads:
Development Environments:
Overall Infrastructure:
The exact savings will depend on your specific workloads, current infrastructure utilization, and implementation details. However, many organizations find that proper workload placement alone can reduce infrastructure costs by 40-60% while maintaining or even improving performance.
Ready to implement this cost-effective MLOps pipeline with Convox? Here's a step-by-step guide:
convox rack install aws production region=us-west-2convox apps create mlops-appconvox.yml with the services and timers outlined aboveconvox apps params set BuildLabels=convox.io/label=ml-build -a mlops-appconvox deploy -a mlops-appImplementation is just the beginning. To maintain cost efficiency, you should:
For mature ML pipelines, you'll want to integrate with a model registry. Here's how you can do this with Convox:
# convox.yml with model registry integration
services:
model-registry:
build: ./registry
port: 8080
scale:
count: 1
cpu: 1024
memory: 2048
nodeSelectorLabels:
convox.io/label: development
volumes:
- name: model-storage
path: /modelsThis creates a central repository for your trained models, allowing for version control and governance of your ML assets.
Building a cost-effective MLOps pipeline doesn't require sacrificing performance or capabilities. With Convox's workload placement features, you can:
By following the approaches outlined in this guide, you can build an MLOps pipeline that not only accelerates your AI development but does so in a way that respects your budget.
Ready to optimize your ML infrastructure costs? Get started with Convox for Free today and see how much you can save while improving your ML operations. For enterprise needs or to discuss larger deployments, reach out to our team at sales@convox.com.